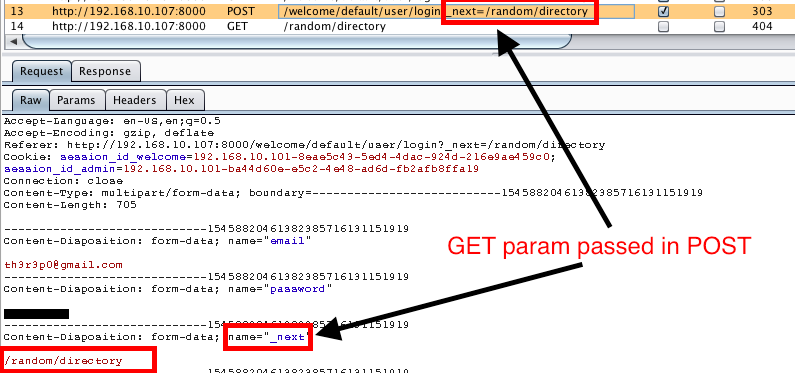
A few days ago I found myself testing a web2py site and upon login, the response redirected you to another page via a 303 redirect. There was a _next parameter set in the GET request to the login page. When the login form was submitted in the POST request, the _next parameter was extracted from the URL and passed in the login form. The _next parameter is used to redirect a user to their last known page in the application or wherever the application developer wants the user to be redirected to upon login.
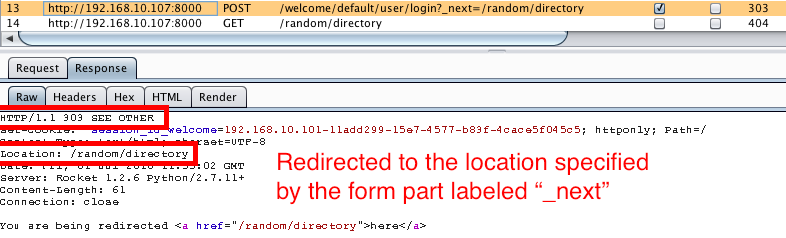
My first thought was to try redirecting to any page I specified within the application and as expected, upon submission of the multipart form, the page redirected me to the page I specified.
The next thing I tested for was whether or not I could redirect to http://www.th3r3p0.com. Unfortunately, this did not work and it redirected me to the default page set by the _next parameter which on the default web2py install that is: /welcome/default/index. I decided to fuzz this parameter a little further and tried http:/www.th3r3p0.com. This time the Location header in the response redirected me to http:/www.th3r3p0.com. For some reason my Firefox browser did not redirect me to this site as I expected it to. Rather, it redirected me to http://192.168.10.107:8000/th3r3p0.com. I then tried http:www.th3r3p0.com and the browser did the exact same redirect as the last request. At a last ditch effort, I tried the following:
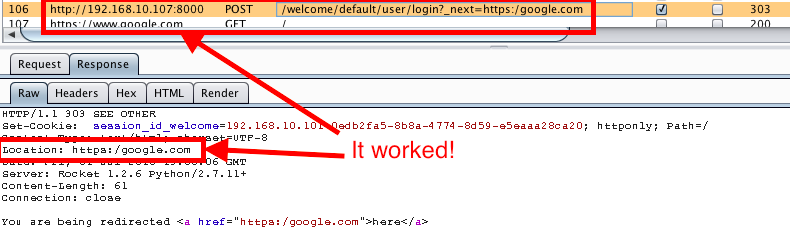
This redirect worked! A few items to note here. 1) The browser auto corrects typos in the URI for when it expects humans make an error. This is the reason the slashes are not needed in the redirect. 2) For some reason, it is necessary to use a different protocol then what the victim URI has specified. For example, if the victim site is on HTTPS then the redirect must be for a HTTP website and vice versa. 3) The reason the redirect did not work for http://th3r3p0.com and it did for https:google.com is because the code before this vulnerability was patched searched for two forward slashes. If the two forward slashes existed in the URI, the hostname had to match the valid hostname. If this did not pass, the next parameter was set to Pythons NoneType which would direct you to the default page set by the application developer. This allowed us to bypass the filter by not using two forward slashes.
I worked with jnbrex to help develop a patch for this vulnerability and submitted a pull request. Within 12 hours mdpierro refactored my request and merged the patch. Please update your web2py framework for the latest security fix by downloading the latest code from the github repository.